Jul 3, 2026
Owned Knowledge Bases Need Searchable AI Retrieval
Owned Knowledge Bases Need Searchable AI Retrieval explains why useful AI memory needs fast capture, visible boundaries, and reusable context rather than another transcript archive.

Self-hosted notes solve only the first half of the ownership problem. The harder half is making that knowledge searchable, permissioned, and reusable by AI agents without turning it into another silo.
Owning notes is not enough
The source threads ask for self-hosted Notion-like knowledge, local agents that can search and fetch, and local file access that works more like web search. The user wants ownership and retrieval in the same layer.
The signal is specific: The row combines self-hosted notes, local agent harnesses, MCP, web search, file indexing, and the frustration that agents can access files without truly searching them. This is not a request for another place to dump notes. It is a request for memory that can be captured quickly, reviewed later, and reused without polluting every future AI session.
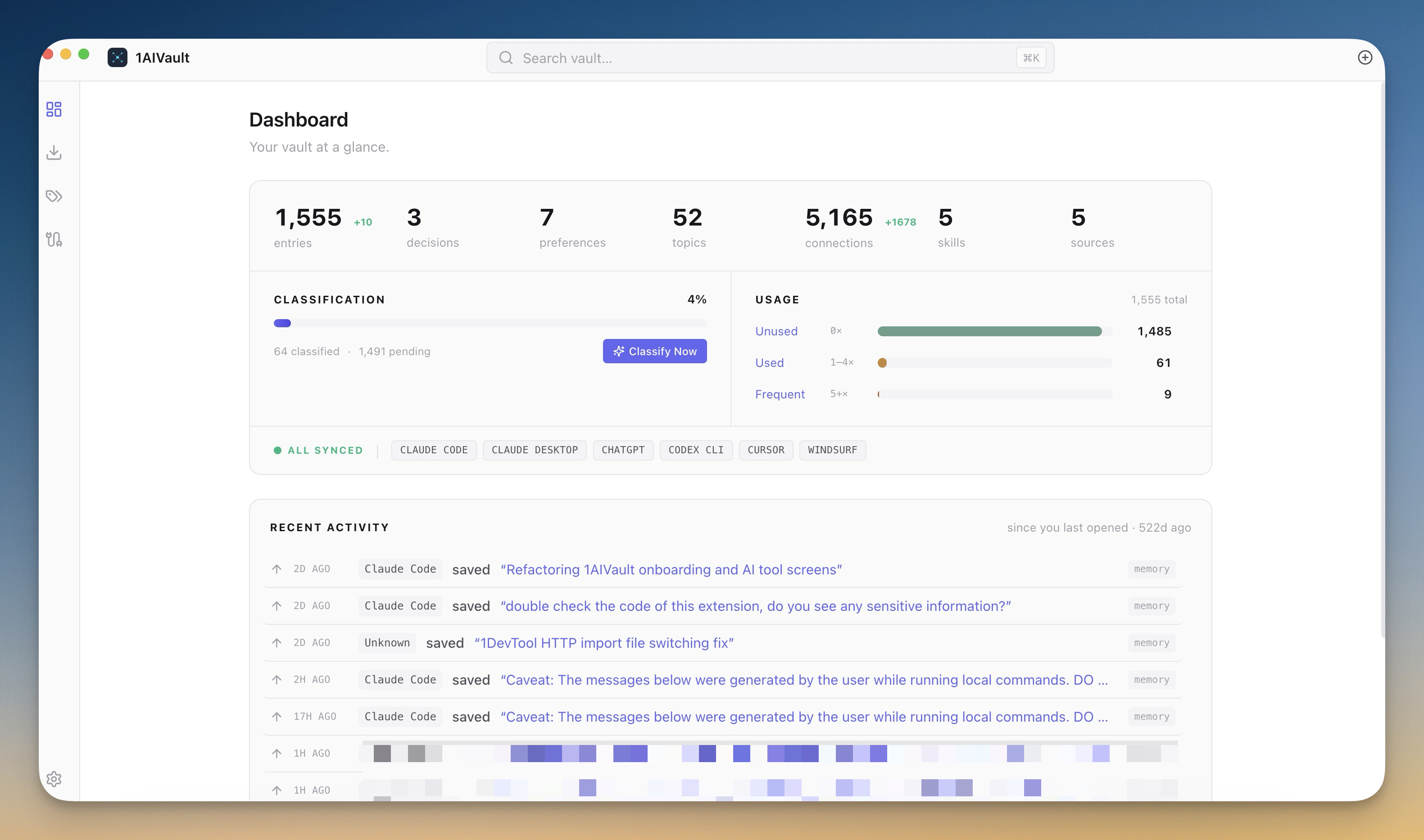 Owned knowledge becomes AI-ready when retrieval, source links, and reusable context live beside the notes.
Owned knowledge becomes AI-ready when retrieval, source links, and reusable context live beside the notes.
The screenshot matters because memory products are otherwise easy to describe vaguely. A visible capture, graph, dashboard, or memory-read surface makes the promise inspectable: context was saved somewhere, came from a source, and can be reviewed before it is reused.
Search has to feed the agent
An owned AI knowledge base needs an index, source-aware summaries, and context packaging. Notes should remain editable by humans while selected fragments become usable input for assistants.
The system has to meet the user before the material is polished. Notes, chat fragments, project decisions, and half-formed ideas should be easy to save first and organize after the useful context is no longer at risk of disappearing.
That timing is the whole product lesson. Memory that asks for perfect taxonomy up front will be bypassed during real work, while memory that accepts rough capture can improve the record once the user has breathing room.
Boundaries make memory trustworthy
Permissions are not optional. Company knowledge, personal notes, commands, and project records need different scopes even when they sit in the same local vault.
AI memory is more sensitive than ordinary note storage because it is designed to be reused. The user needs to know what was captured, where it came from, who can read it, and whether an assistant is allowed to write back into the vault.
Reuse is different from storage
The agent should not receive a dump of everything. It should receive the smallest source-linked packet that answers the current task and can be audited afterward.
A transcript archive can answer "what did I say?" A reusable memory layer should answer "what context helps this task now?" That requires summaries, source links, freshness, and small context packets instead of indiscriminate recall.
Maintenance is part of the product
The next knowledge base is not just self-hosted. It is owned, searchable, and ready to become context on purpose.
Memory that cannot be pruned becomes another inbox. The durable version is local, inspectable, and willing to treat forgetting as a feature when old context would make the next task worse.