Jun 3, 2026
MCP builders are quietly rebuilding the same vault — there should be a default layer underneath
Every new MCP server reinvents prompt storage, note storage, key storage, and context recall. A reusable vault layer underneath MCP would let server authors stop building memory and start building tools.
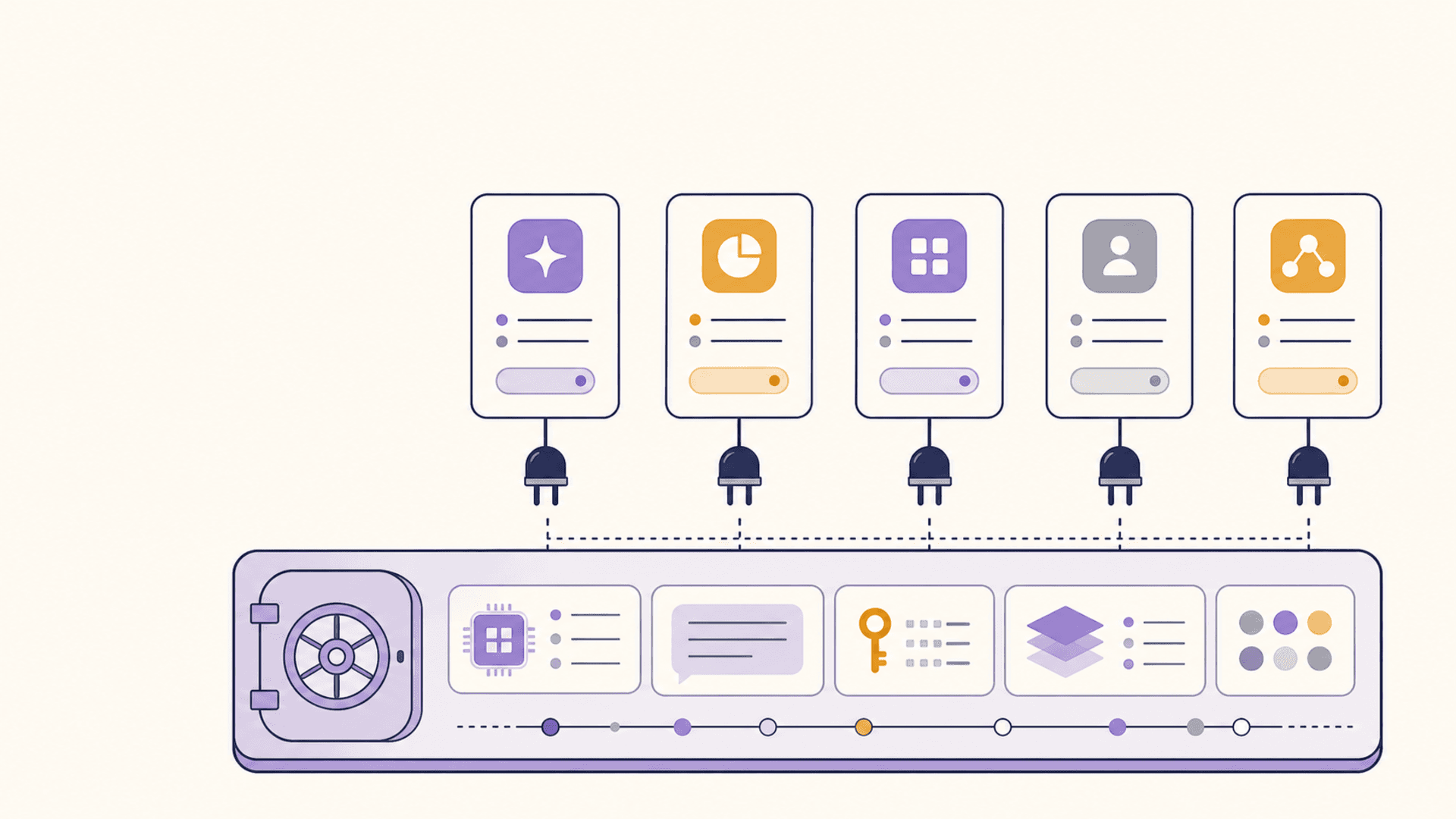
Look at the last five MCP servers that landed in your timeline. Then look at what each of them actually built.
One shipped a memory tool — so it added a storage backend, an embeddings pipeline, a search index, and a CRUD surface. One shipped a prompt-library tool — same thing, different schema: storage, search, list, get, save. One shipped a credentials helper — storage, list, get, set. One shipped a research notebook — storage, tagging, link graph, search. One shipped a "context" tool — storage, conversation logs, recall.
Five servers. Five almost-identical storage layers. Five different places your data lives. Five sets of trust decisions to make about each one.
The protocol that was supposed to unbundle tools accidentally bundled storage into every single one.
What MCP got right, and what it left out
MCP nailed the boundary between the model client and the tool. A server exposes capabilities; a client decides when to call them. That contract is clean. It made it possible for a Claude Desktop user, a Cursor user, and a Cline user to all reach the same tool without that tool caring which client is on the other end.
But the protocol said nothing about where the durable state underneath a tool should live. So every server author makes the obvious choice: ship their own. SQLite under ~/.local/share/<tool>. JSON in a config folder. A cloud backend with an API key the user is expected to manage. Whatever was easiest the day they started.
If you use five MCP tools, you now have five different storage substrates running. None of them know about each other. Your prompts in one, your memories in another, your snippets in a third, your saved web clippings in a fourth. The whole point of MCP was that the tools don't need to know about each other. The data underneath them does.
The repeated work, in concrete terms
When an MCP server author sits down to build a new tool, here is what they end up writing before they get to the actual interesting part:
- A storage engine (SQLite is the popular default; a few use Postgres; a few use flat files).
- A schema for whatever the unit is — "memory", "prompt", "note", "snippet", "document".
- A search layer, often FTS, sometimes embeddings, occasionally a vector DB dependency.
- A list/get/save/delete CRUD shell.
- Encryption-at-rest, maybe, if they're disciplined about it.
- Backup, export, and migration paths.
- A tagging or grouping model so users can organize.
- A way to share or sync to another device.
- Auth, if it's not strictly local.
None of that is unique to what the tool does. It's just the substrate every information-storage tool needs. And it gets rebuilt every time because there is no convention for outsourcing it.
What a default vault layer would look like
Imagine the MCP ecosystem assumed there was a vault. A local-first, encrypted-by-default, user-owned blob store with primitives for entries, tags, links, and search. Server authors would call out to it the same way web apps call out to Postgres — not as a feature, as a given.
A prompt-library server would store its prompts in the vault. A memory server would store its memories in the vault. A snippet manager would store snippets in the vault. The vault wouldn't care which type of entry it was holding; each server would tag its own entries and only see what it owns by default, but the user could see all of them in one place.
That single shift changes a lot of things at once.
For server authors, the boring half of every project goes away. You import a vault client. You add vault.save({ type: 'prompt', content, tags }) and vault.search({ type: 'prompt', q }). You ship a tool that does the interesting part of your idea, not the bookkeeping.
For users, the data fragmentation stops. There is one place memories live, one place prompts live, one place credentials live — and one place to audit, back up, and move them when the user switches machines or clients.
For the ecosystem, trust gets cheaper. Today, installing a new MCP server means evaluating its storage, its sync model, its encryption story, its export story. A default vault layer makes those evaluations one-time decisions instead of per-tool ones.
Why this hasn't happened yet
The MCP spec is deliberately small. It does not, and probably should not, mandate a storage substrate. What's missing isn't a protocol change — it's a convention and a reference implementation that's good enough that nobody wants to write their own.
The reference implementation has to be:
- Local-first. Not a cloud service with a free tier. Not something that breaks when offline. Your prompts and credentials should not need a network.
- Encrypted by default. Credentials and personal notes belong in an encrypted store, not a plaintext SQLite file with a TODO comment about it.
- MCP-native. It should expose itself as an MCP server too, so the same vault that backs your other tools is also reachable directly from your client.
- Schema-flexible. A prompt is not a memory is not a credential. The vault has to hold heterogeneous typed entries and let each tool work with its own type.
- Portable. Export and import should be one command, because the user owns the data and might leave at any time.
None of those are hard problems individually. The hard problem is shipping a single project that nails all of them and makes it the obvious default.
What this means for builders right now
If you are about to build an MCP server, ask whether your tool needs storage as a first-class concern or whether storage is the boring substrate underneath a smarter idea. If the answer is the second one, look at whether you can build on top of a vault layer instead of reinventing one.
If you are using a stack of MCP servers today, audit where each of them is putting your data. If you can already identify three different folders, three different sync stories, and three different export procedures, that is the cost of the missing layer showing up in your own setup.
The protocol unbundled the tools. The next step is unbundling the substrate too — so MCP servers can ship as tools, and the user's data lives in one durable place underneath them.