Jun 3, 2026
Power users compare AI coding tools — the real pain is fractured memory between them
Comparison posts focus on which AI coding tool is best. The hidden cost is the constant switching: Cursor today, Claude Code tomorrow, Copilot at the office, with no shared memory between them. A vault closes the gap the comparisons can't.
Read enough "I tested every AI coding tool" posts and a strange thing becomes apparent. The conclusions are about quality, speed, autonomy, model choice — the things you'd expect a comparison to focus on. They're useful comparisons.
But what they don't talk about is the thing the author is doing throughout the test: switching between tools. Spending a week in Cursor, then a week in Claude Code, then a week in Copilot, then back to Cursor for context. Each switch starts over.
The author probably didn't notice it as a measurable cost because it was background noise. They re-pasted the project description, re-explained the stack, re-mentioned the customer constraints, re-named the conventions. Every test week began with that ritual. The comparison evaluated the tool but didn't evaluate the transition into the tool.
That transition cost — fractured memory across tools — is the real thing slowing power users down. The tool quality comparisons don't surface it because it's not in any single tool's surface to fix.
Why fractured memory hides in plain sight
When the user is fluent in their own context, they barely register the cost of re-pasting it. The re-paste happens fast. The model picks up quickly. The user feels like the new tool is good — and it is — but they don't tally the minutes they just spent rebuilding what the previous tool already knew.
Multiplied across a week of tool-comparison testing, the cost is real. Multiplied across the months a normal developer cycles between Cursor and Claude Code and a custom MCP client and ChatGPT, the cost is bigger than any individual tool's marginal improvement.
The comparison framing misses this because it's tool-by-tool. The remedy is layered: not which tool is best, but what substrate lives underneath all of them.
What "fractured memory" actually means for coding
A few concrete examples of what fractures every time:
- The stack you're working in. The user explains it again in each tool.
- The naming conventions the codebase uses. Each tool re-learns it.
- The customer or project the work is for. Each tool re-encounters the constraint.
- The list of files or modules the user has been touching. Each tool starts cold.
- The recent decisions — "we decided not to use v4 yet because of the auth break" — that each tool would benefit from but doesn't see unless the user re-explains.
- The personal preferences the user has — verbose docs vs minimal, what to leave out, what to assume — that each tool re-derives from scratch.
Individually each item is a small re-paste. Collectively they form the "setup paragraph" the user types at the start of every new tool session. The setup paragraph rarely makes it into the comparison post, but it's there in every workflow.
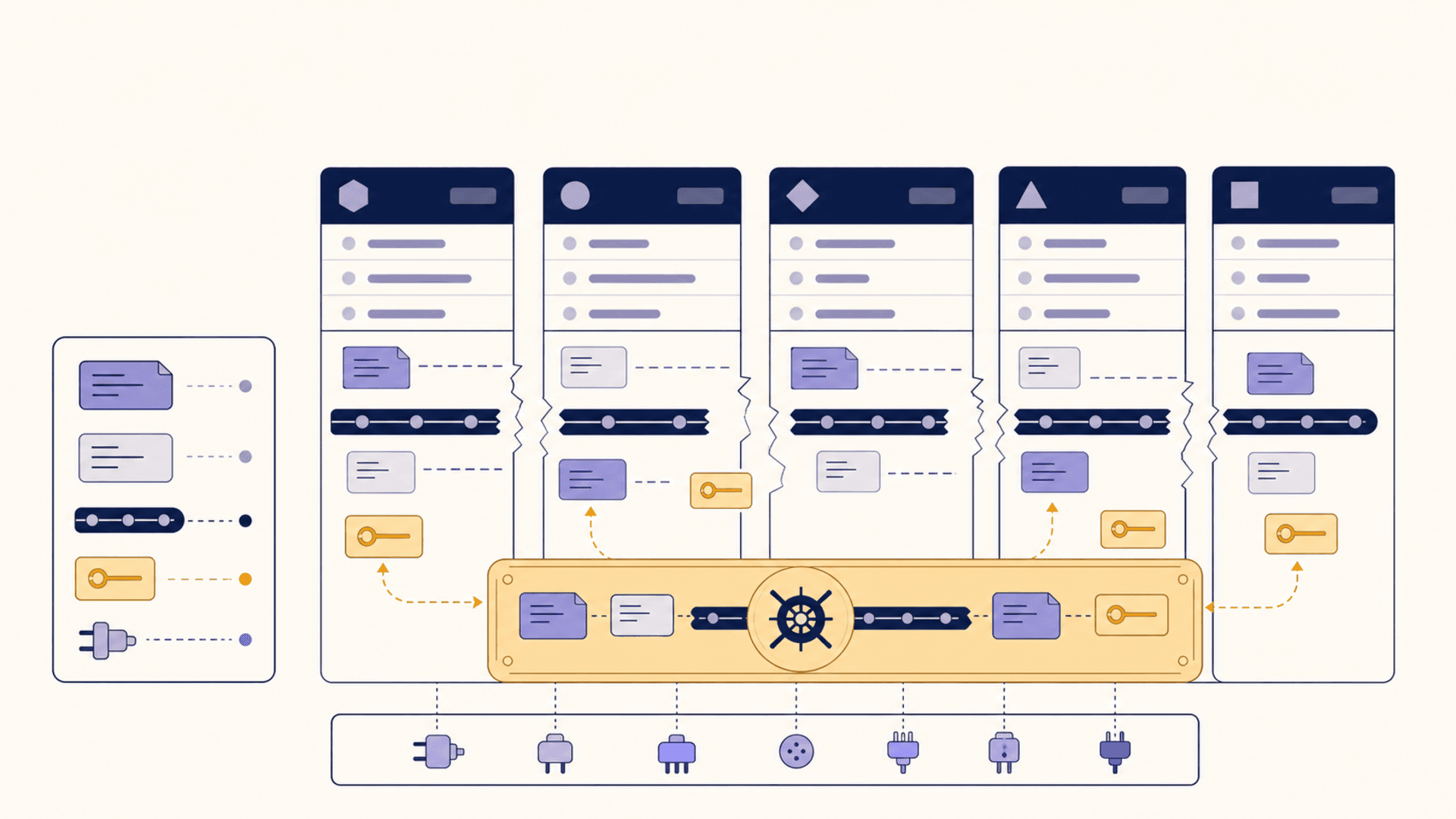
What a vault changes in a coding workflow
Move the setup paragraph into a vault and the dynamic flips. Each tool opens with the substrate already loaded. The user does not re-paste. The comparison between tools becomes a comparison between the tools themselves rather than between "tool plus its onboarding overhead."
Concretely:
Project context is loaded automatically. A new Cursor session sees the stack, the conventions, the customer constraints, the active project. The same in Claude Code. The same in Copilot if a connector exists.
Recent decisions are carried. "We decided not to upgrade v4 yet" sits in the vault. Whichever tool the user opens later that week sees that decision. The model doesn't suggest the upgrade. The user doesn't have to re-explain it.
Standing prompts are shared. The user's code-review prompt lives in the vault and surfaces in every client. The user's commit-message prompt lives in the vault and surfaces in every client.
Snippets propagate. A small reusable helper the user trusts lives in the vault. Whichever tool needs it can fetch it.
Credentials are scoped. GitHub tokens, deploy keys, API keys for the LLM the tool itself uses — all scoped to the project, all sourced from the vault rather than scattered in .env files.
With the vault as substrate, the tool comparisons become honest. Each tool's strengths shine without the setup overhead getting credited or debited.
What an honest tool comparison looks like with a vault
If you re-run the standard "AI coding tool comparison" with a vault sitting underneath every tool, the conclusions shift.
- Tools that are good at speed get credited for speed without their cold-start tax.
- Tools that have great agentic autonomy get judged on autonomy without the user being judged for re-pasting setup at the start.
- Tools whose UX is great get the credit for UX without the user's frustration at the substrate fragmentation being conflated with the tool itself.
In short, the comparison stops being polluted by the cross-tool setup cost. The author can write about quality, speed, autonomy, model behavior — the things they actually wanted to compare — because the substrate fragmentation is no longer doing the talking.
What this means for the comparison economy
A lot of writing energy goes into AI coding tool comparisons. Some of it is informative; some of it is performance. The honest comparisons would shift in one of two directions.
One direction: explicitly name the substrate fragmentation as the bigger problem. "All these tools are pretty good once you load them up with context. The real cost is loading them up. Here's the layer that fixes it." That makes the comparison useful in a new way.
The other direction: assume the substrate is in place and write cleaner tool comparisons. "With a vault running underneath, here's how Cursor, Claude Code, and Copilot actually feel head-to-head." The substrate becomes a baseline.
Either way, the comparison stops being about loneliness. It starts being about the tools at their fairest.
What this means for developers picking tools today
The practical implication for a developer choosing AI tools right now is: pick the substrate before you pick the client.
Most developers do the opposite. They try Cursor for a week, Claude Code for a week, Cline for a week, settling on whichever client matches their hands. Then they suffer through the next year of context fragmentation because no two clients share state.
Pick the substrate — the vault that holds your prompts, memories, snippets, credentials — and then your client choice becomes downstream. Change clients as often as you want; the substrate carries forward. The work compounds across the tool churn instead of resetting at each switch.
What this means for vault builders
If you build a vault, you don't have to compete with AI coding tools — you complement them. Your story is "we make every tool you use better by giving them shared substrate."
That positioning sidesteps the tool wars entirely. You're not arguing Cursor vs Claude Code. You're arguing that whichever tool the user picks today should benefit from the work they did in last week's tool. That's a story the comparison authors should have been telling, and it leaves a clean lane for the vault to take.
The summary
The AI coding tool comparisons miss the load-bearing cost of context switching. Power users switch constantly, lose memory at each switch, and pay the cost without naming it. A vault that holds shared substrate beneath every client closes that gap. Pick the substrate first; the client choice gets easier. Build the vault; the comparison becomes about the tools themselves rather than about each tool's onboarding.